Publications
2026
- Preprint
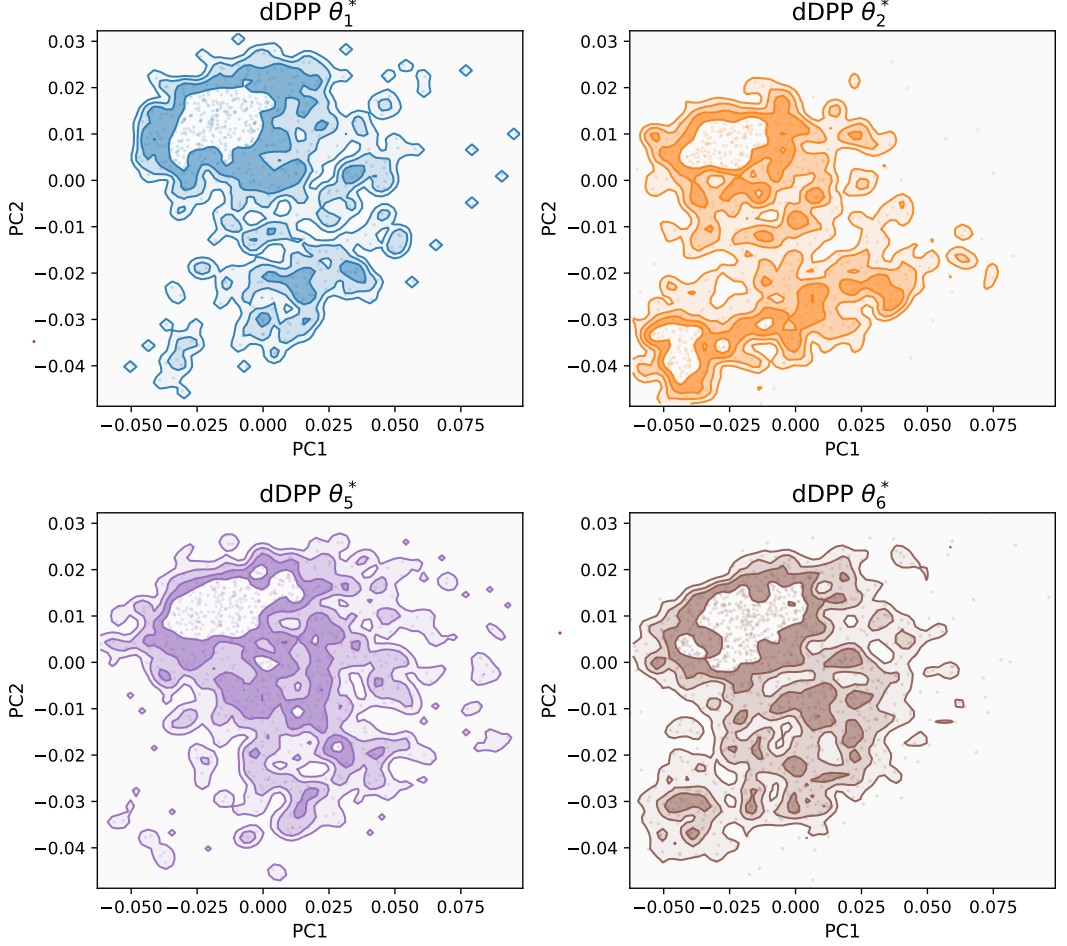 Distributional Determinantal Point Process for Repulsive Clustering of DistributionsKhai Nguyen, Yang Ni, Elizabeth Juarez-Colunga, and 1 more authorUnder Review, 2026
Distributional Determinantal Point Process for Repulsive Clustering of DistributionsKhai Nguyen, Yang Ni, Elizabeth Juarez-Colunga, and 1 more authorUnder Review, 2026We introduce the distributional determinantal point process (dDPP) as a novel repulsive point process whose atoms are probability distributions rather than points in a real space. The dDPP is constructed via an L-ensemble with a sliced Wasserstein (SW) kernel between distributions. We show its validity as a well-defined point process. In the discrete setting, we derive concentration results for plug-in estimators of the L-ensemble, the correlation kernel, and their determinants given i.i.d. samples from the distributional atoms. Leveraging this framework, we propose a distribution-valued random partition model by way of a repulsive generalized Bayesian mixture model. The model places a dDPP prior over the atoms of the mixing measure and defines a generalized likelihood based on SW distance. To summarize posterior inference, we develop a decision-theoretic approach to report a point estimate of the mixing measure as a Bayes rule under a hierarchical optimal transport utility function. The latter is a natural choice given that the mixing measure is itself a distribution over distributions. We use the proposed framework for inference with single-cell gene expression data and human epilepsy data, producing interpretable and well-separated clusters that reflect meaningful structure in the data.
- Streaming Sliced Optimal TransportKhai NguyenInternational Conference on Machine Learning, 2026
Sliced optimal transport (SOT) or sliced Wasserstein (SW) distance is widely recognized for its statistical and computational scalability. In this work, we further enhance the computational scalability by proposing the first method for computing SW from sample streams, called \emphstreaming sliced Wasserstein (Stream-SW). To define Stream-SW, we first introduce the streaming computation of the one-dimensional Wasserstein distance. Since the one-dimensional Wasserstein (1DW) distance has a closed-form expression, given by the absolute difference between the quantile functions of the compared distributions, we leverage quantile approximation techniques for sample streams to define the streaming 1DW distance. By applying streaming 1DW to all projections, we obtain Stream-SW. The key advantage of Stream-SW is its low memory complexity while providing theoretical guarantees on the approximation error. We demonstrate that Stream-SW achieves a more accurate approximation of SW than random subsampling, with lower memory consumption, in comparing Gaussian distributions and mixtures of Gaussians from streaming samples. Additionally, we conduct experiments on point cloud classification, point cloud gradient flows, and streaming change point detection to further highlight the favorable performance of Stream-SW
- Preprint
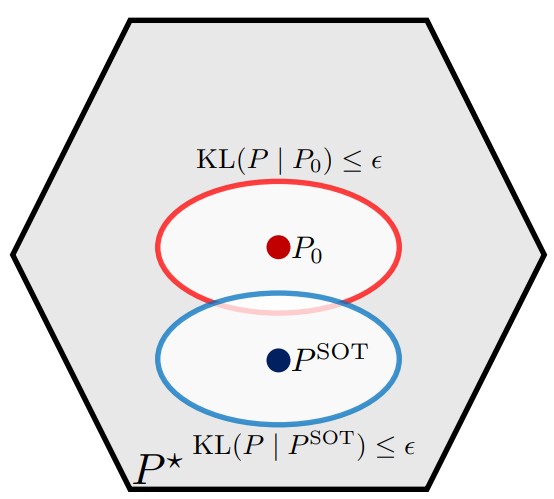 Sliced-Regularized Optimal TransportKhai NguyenUnder Review, 2026Poster at STAI-X 2026
Sliced-Regularized Optimal TransportKhai NguyenUnder Review, 2026Poster at STAI-X 2026We propose a new regularized optimal transport (OT) formulation, termed sliced-regularized optimal transport (SROT). Unlike entropic OT (EOT), which regularizes the transport plan toward an independent coupling, SROT regularizes it toward a smoothened sliced OT (SOT) plan. To the best of our knowledge, SROT is the first approach to leverage a version of SOT plan as a reference to improve classical OT. We provide a formal definition of SROT, derive its dual formulation, and provide a post-Bayesian interpretation of SROT. We then develop a Sinkhorn-style algorithm for efficient computation, retaining the same scalability advantages as EOT. By incorporating a scalable SOT plan as a prior, SROT yields more accurate approximations of the exact OT plan than EOT under the same level of regularization. Moreover, the resulting transport plan improves upon the reference SOT plan itself. We further introduce the corresponding OT divergence induced by SROT, named SROT divergence, and analyze its topological and computational properties. Finally, we validate our approach through experiments on synthetic datasets and color transfer tasks, demonstrating that SROT is better than both EOT and SOT in approximating exact OT. Additional experiments on gradient flows further highlight the advantages of SROT divergence.
- Preprint
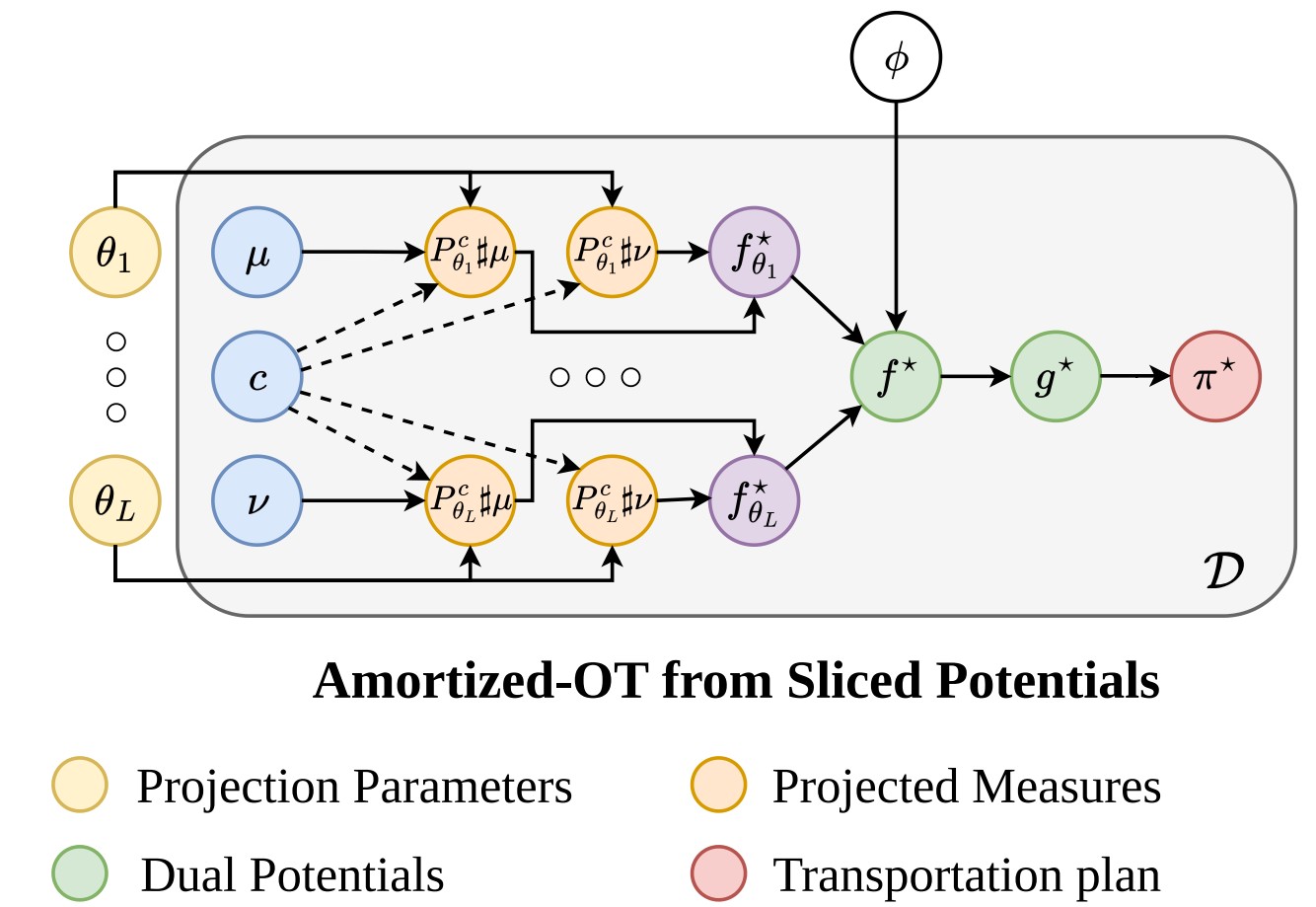 Amortized Optimal Transport from Sliced PotentialsMinh-Phuc Truong , and Khai NguyenUnder Review, 2026
Amortized Optimal Transport from Sliced PotentialsMinh-Phuc Truong , and Khai NguyenUnder Review, 2026We propose a novel amortized optimization method for predicting optimal transport (OT) plans across multiple pairs of measures by leveraging Kantorovich potentials derived from sliced OT. We introduce two amortization strategies: regression-based amortization (RA-OT) and objective-based amortization (OA-OT). In RA-OT, we formulate a functional regression model that treats Kantorovich potentials from the original OT problem as responses and those obtained from sliced OT as predictors, and estimate these models via least-squares methods. In OA-OT, we estimate the parameters of the functional model by optimizing the Kantorovich dual objective. In both approaches, the predicted OT plan is subsequently recovered from the estimated potentials. As amortized OT methods, both RA-OT and OA-OT enable efficient solutions to repeated OT problems across different measure pairs by reusing information learned from prior instances to rapidly approximate new solutions. Moreover, by exploiting the structure provided by sliced OT, the proposed models are more parsimonious, independent of specific structures of the measures, such as the number of atoms in the discrete case, while achieving high accuracy. We demonstrate the effectiveness of our approaches on tasks including MNIST digit transport, color transfer, supply-demand transportation on spherical data, and mini-batch OT conditional flow matching.
- PreprintStellar Abstract
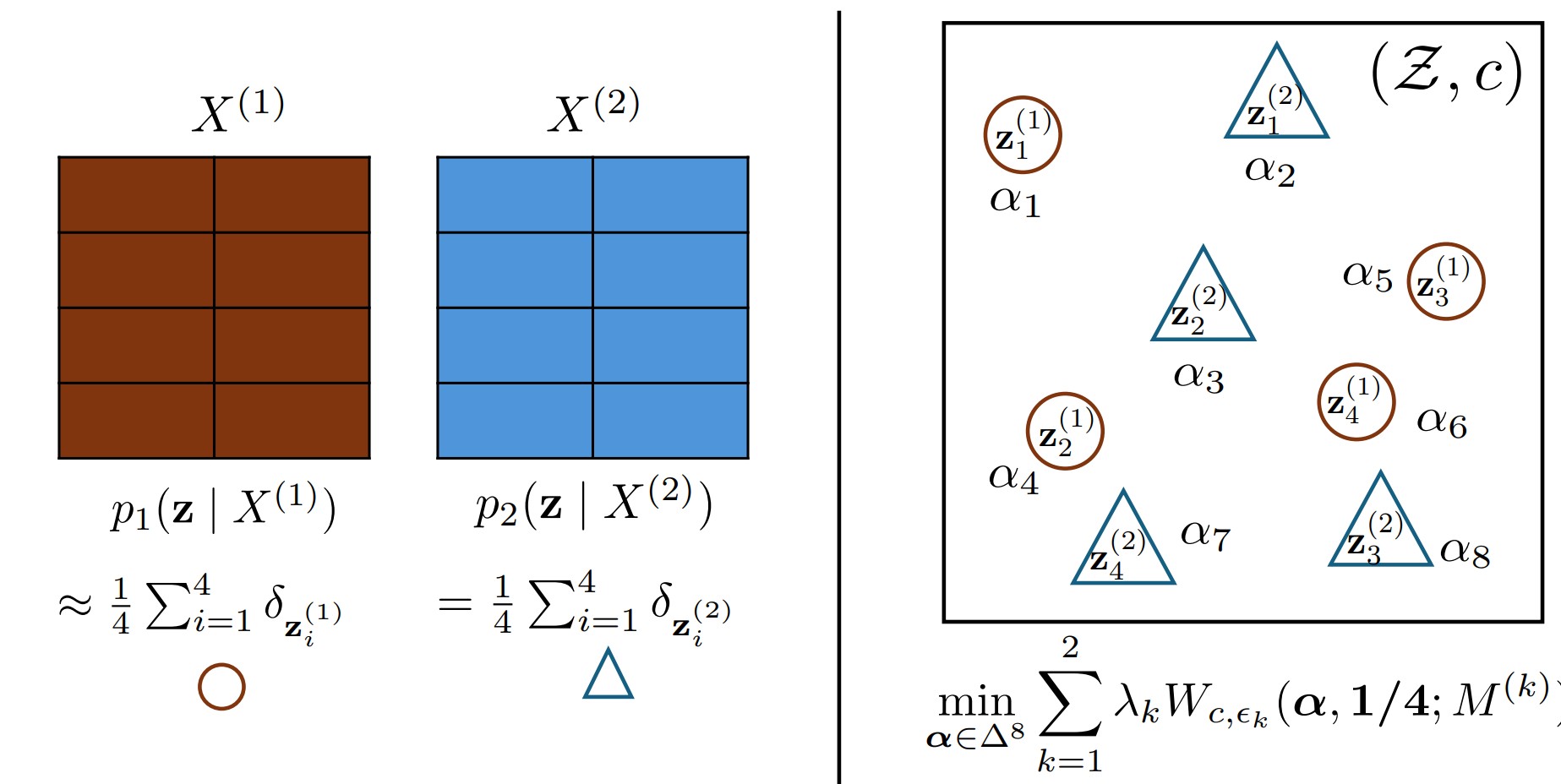 Vertical Consensus Inference for High-Dimensional Random PartitionKhai Nguyen, Yang Ni, and Peter MuellerUnder Review, 2026Stellar Abstract Award at STAI-X 2026
Vertical Consensus Inference for High-Dimensional Random PartitionKhai Nguyen, Yang Ni, and Peter MuellerUnder Review, 2026Stellar Abstract Award at STAI-X 2026Stellar Abstract
We review recently proposed Bayesian approaches for clustering high-dimensional data. After identifying the main limitations of available approaches, we introduce an alternative framework based on vertical consensus inference (VCI) to mitigate the curse of dimensionality in high-dimensional Bayesian clustering. VCI builds on the idea of consensus Monte Carlo by dividing the data into multiple shards (smaller subsets of variables), performing posterior inference on each shard, and then combining the shard-level posteriors to obtain a consensus posterior. The key distinction is that VCI splits the data vertically, producing vertical shards that retain the same number of observations but have lower dimensionality. We use an entropic regularized Wasserstein barycenter to define a consensus posterior. The shard-specific barycenter weights are constructed to favor shards that provide meaningful partitions, distinct from a trivial single cluster or all singleton clusters, favoring balanced cluster sizes and precise shard-specific posterior random partitions. We show that VCI can be interpreted as a variational approximation to the posterior under a hierarchical model with a generalized Bayes prior. For relatively low-dimensional problems, experiments suggest that VCI closely approximates inference based on clustering the entire multivariate data. For high-dimensional data and in the presence of many noninformative dimensions, VCI introduces a new framework for model-based and principled inference on random partitions. Although our focus here is on random partitions, VCI can be applied to any dimension-independent parameters and serves as a bridge to emerging areas in statistics such as consensus Monte Carlo, optimal transport, variational inference, and generalized Bayes.
- Preprint
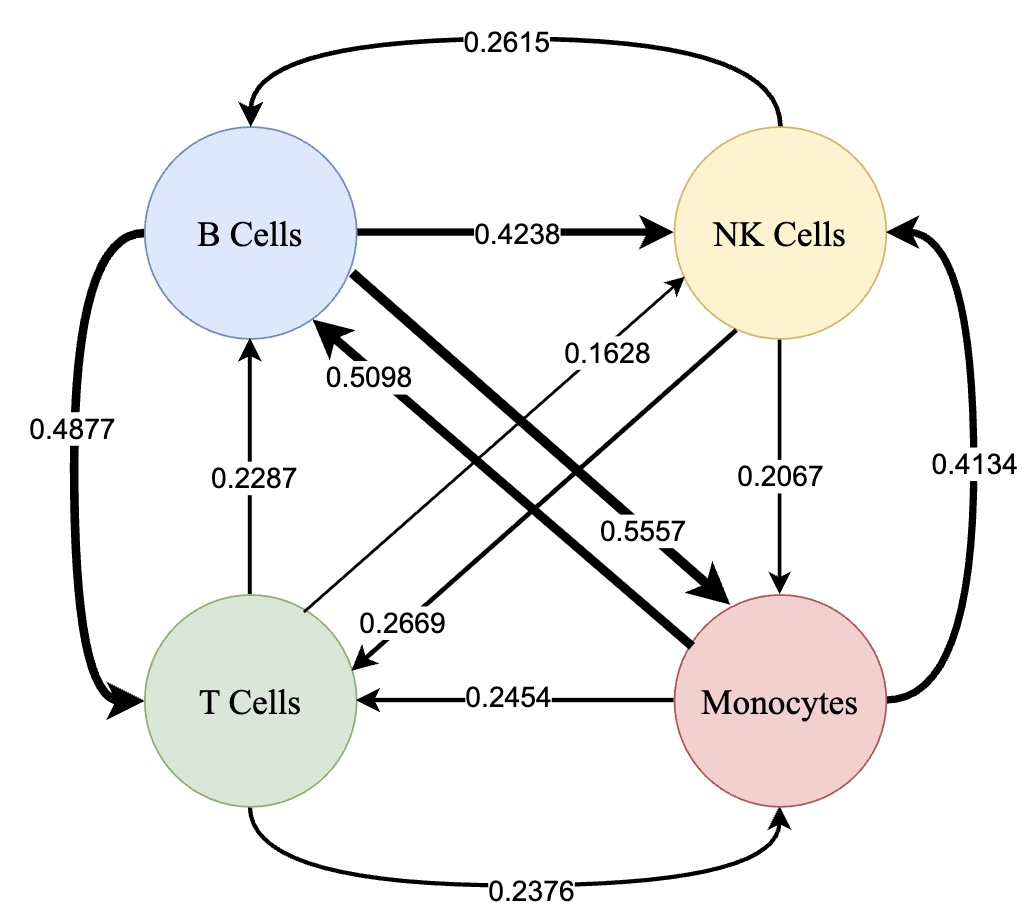 Bayesian Multiple Multivariate Density-Density RegressionKhai Nguyen, Yang Ni, and Peter MuellerUnder Review, 2026Contributed Talk at COTS 2026
Bayesian Multiple Multivariate Density-Density RegressionKhai Nguyen, Yang Ni, and Peter MuellerUnder Review, 2026Contributed Talk at COTS 2026We propose the first approach for multiple multivariate density-density regression (MDDR), making it possible to consider the regression of a multivariate density-valued response on multiple multivariate density-valued predictors. The core idea is to define a fitted distribution using a sliced Wasserstein barycenter (SWB) of push-forwards of the predictors and to quantify deviations from the observed response using the sliced Wasserstein (SW) distance. Regression functions, which map predictors’ supports to the response support, and barycenter weights are inferred within a generalized Bayes framework, enabling principled uncertainty quantification without requiring a fully specified likelihood. The inference process can be seen as an instance of an inverse SWB problem. We establish theoretical guarantees, including the stability of the SWB under perturbations of marginals and barycenter weights, sample complexity of the generalized likelihood, and posterior consistency. For practical inference, we introduce a differentiable approximation of the SWB and a smooth reparameterization to handle the simplex constraint on barycenter weights, allowing efficient gradient-based MCMC sampling. We demonstrate MDDR in an application to inference for population-scale single-cell data. Posterior analysis under the MDDR model in this example includes inference on communication between multiple source/sender cell types and a target/receiver cell type. The proposed approach provides accurate fits, reliable predictions, and interpretable posterior estimates of barycenter weights, which can be used to construct sparse cell-cell communication networks.
- Summarizing Nonparametric Bayesian Mixture Posterior–Sliced Optimal Transport Metrics for Gaussian MixturesKhai Nguyen, and Peter MuellerJournal of Computational and Graphical Statistics, 2026Contributed Talk at BNP14, Talk in session with discussion at BAYSM25
Existing methods to summarize posterior inference for mixture models focus on identifying a point estimate of the implied random partition for clustering, with density estimation as a secondary goal (Wade and Ghahramani, 2018; Dahl et al., 2022). We propose a novel approach for summarizing posterior inference in nonparametric Bayesian mixture models, prioritizing density estimation of the mixing measure (or mixture) as an inference target. One of the key features is the model-agnostic nature of the approach, which remains valid under arbitrarily complex dependence structures in the underlying sampling model. Using a decision-theoretic framework, our method identifies a point estimate by minimizing posterior expected loss. A loss function is defined as a discrepancy between mixing measures. Estimating the mixing measure implies inference on the mixture density. Exploiting the discrete nature of the mixing measure, we use a version of sliced Wasserstein distance. We introduce two specific variants for Gaussian mixtures. The first, mixed sliced Wasserstein, applies generalized geodesic projections on the product of the Euclidean space and the manifold of symmetric positive definite matrices. The second, sliced mixture Wasserstein, leverages the linearity of Gaussian mixture measures for efficient projection.
- Preprint
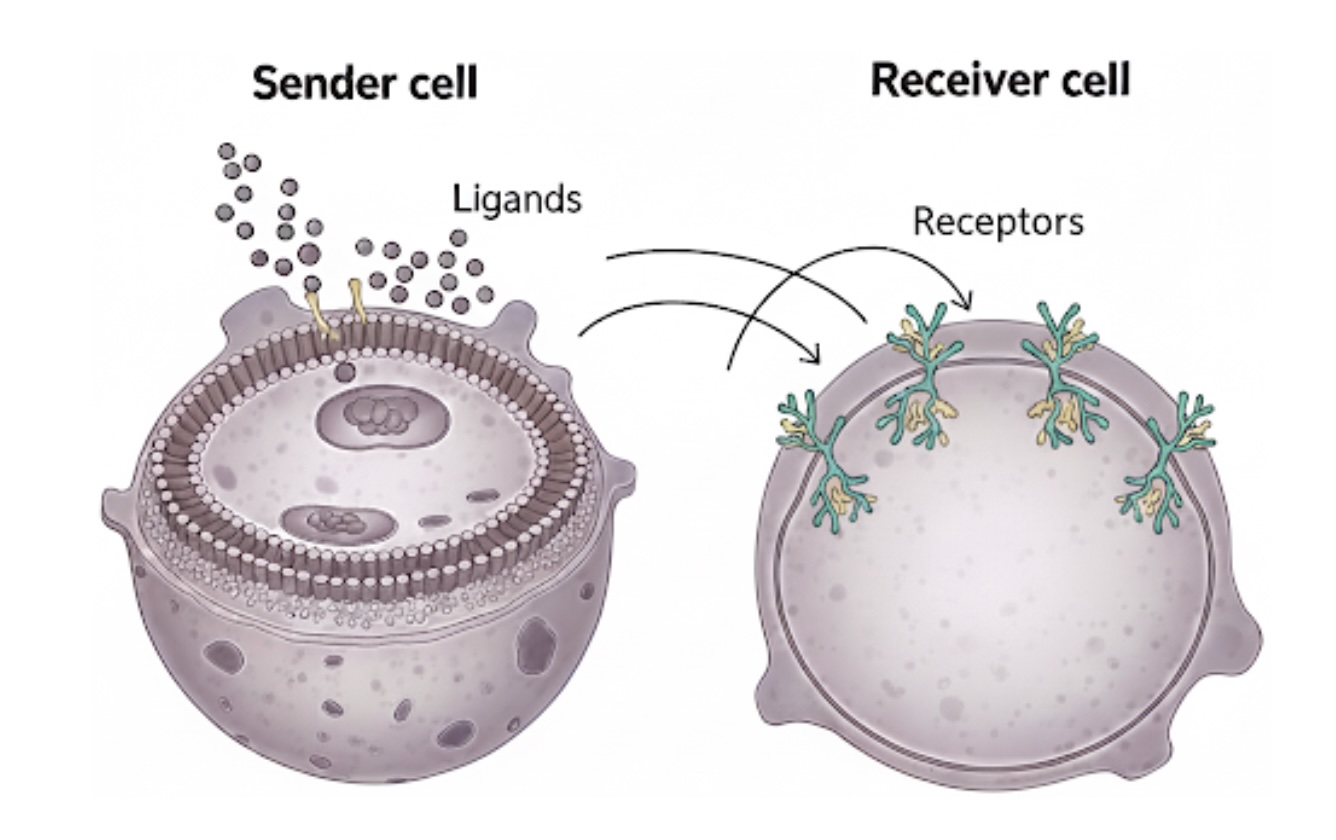 Bayesian Multivariate Density-Density RegressionKhai Nguyen, Yang Ni, and Peter MuellerUnder major revision at Bayesian Analysis, 2026
Bayesian Multivariate Density-Density RegressionKhai Nguyen, Yang Ni, and Peter MuellerUnder major revision at Bayesian Analysis, 2026We introduce a scalable framework for regressing multivariate distributions onto multivariate distributions, motivated by the application of inferring cell-cell communication from population-scale single-cell data. The observed data consist of pairs of multivariate distributions for ligands from one cell type and corresponding receptors from another. For each ordered pair e=(l,r) of cell types (l≠r) and each sample i=1,…,n, we observe a pair of distributions (Fei,Gei) of gene expressions for ligands and receptors of cell types l and r, respectively. The aim is to set up a regression of receptor distributions Gei given ligand distributions Fei. A key challenge is that these distributions reside in distinct spaces of differing dimensions. We formulate the regression of multivariate densities on multivariate densities using a generalized Bayes framework with the sliced Wasserstein distance between fitted and observed distributions. Finally, we use inference under such regressions to define a directed graph for cell-cell communications.
- Fast Estimation of Wasserstein Distances via Regression on Sliced Wasserstein DistancesKhai Nguyen* , Hai Nguyen*, and Nhat HoInternational Conference on Learning Representations, 2026
We address the problem of efficiently computing Wasserstein distances for multiple pairs of distributions drawn from a meta-distribution. To this end, we propose a fast estimation method based on regressing Wasserstein distance on sliced Wasserstein (SW) distances. Specifically, we leverage both standard SW distances, which provide lower bounds, and lifted SW distances, which provide upper bounds, as predictors of the true Wasserstein distance. To ensure parsimony, we introduce two linear models: an unconstrained model with a closed-form least-squares solution, and a constrained model that uses only half as many parameters. We show that accurate models can be learned from a small number of distribution pairs. Once estimated, the model can predict the Wasserstein distance for any pair of distributions via a linear combination of SW distances, making it highly efficient. Empirically, we validate our approach on diverse tasks, including Gaussian mixtures, point-cloud classification, and Wasserstein-space visualizations for 3D point clouds. Across various datasets such as MNIST point clouds, ShapeNetV2, MERFISH Cell Niches, and scRNA-seq, our method consistently provides a better approximation of Wasserstein distance than the state-of-the-art Wasserstein embedding model, Wasserstein Wormhole, particularly in low-data regimes. Finally, we demonstrate that our estimator can also accelerate Wormhole training, yielding \textitRG-Wormhole









2025
- An Introduction to Sliced Optimal Transport: Foundations, Advances, Extensions, and ApplicationsKhai NguyenFoundations and Trends® in Computer Graphics and Vision, 2025
Sliced Optimal Transport (SOT) is a rapidly developing branch of optimal transport (OT) that exploits the tractability of one-dimensional OT problems. By combining tools from OT, integral geometry, and computational statistics, SOT enables fast and scalable computation of distances, barycenters, and kernels for probability measures, while retaining rich geometric structure. This monograph provides a comprehensive review of SOT, covering its mathematical foundations, methodological advances, computational methods, and applications. We discuss key concepts of OT and one-dimensional OT, the role of tools from integral geometry such as Radon transform in projecting measures, and statistical techniques for estimating sliced distances. The monograph further explores recent methodological advances, including non-linear projections, improved Monte Carlo approximations, statistical estimation techniques for one-dimensional optimal transport, weighted slicing techniques, and transportation plan estimation methods. Variational problems, such as minimum sliced Wasserstein estimation, barycenters, gradient flows, kernel constructions, and embeddings are examined alongside extensions to unbalanced, partial, multi-marginal, and Gromov-Wasserstein settings. Applications span machine learning, statistics, computer graphics and computer visions, highlighting SOT’s versatility as a practical computational tool. This work will be of interest to researchers and practitioners in machine learning, data sciences, and computational disciplines seeking efficient alternatives to classical OT.
- Unbiased Sliced Wasserstein Kernels for High-Quality Audio CaptioningManh Luong , Khai Nguyen, Dinh Phung, and 2 more authorsNeural Information Processing Systems, 2025
Teacher-forcing training for audio captioning usually leads to exposure bias due to training and inference mismatch. Prior works propose the contrastive method to deal with caption degeneration. However, the contrastive method ignores the temporal information when measuring similarity across acoustic and linguistic modalities, leading to inferior performance. In this work, we develop the temporal-similarity score by introducing the unbiased sliced Wasserstein RBF (USW-RBF) kernel equipped with rotary positional embedding to account for temporal information across modalities. In contrast to the conventional sliced Wasserstein RBF kernel, we can form an unbiased estimation of USW-RBF kernel via Monte Carlo estimation. Therefore, it is well-suited to stochastic gradient optimization algorithms, and its approximation error decreases at a parametric rate with Monte Carlo samples. Additionally, we introduce an audio captioning framework based on the unbiased sliced Wasserstein kernel, incorporating stochastic decoding methods to mitigate caption degeneration during the generation process. We conduct extensive quantitative and qualitative experiments on two datasets, AudioCaps and Clotho, to illustrate the capability of generating high-quality audio captions. Experimental results show that our framework is able to increase caption length, lexical diversity, and text-to-audio self-retrieval accuracy
- Lightspeed Geometric Dataset Distance via Sliced Optimal TransportKhai Nguyen* , Hai Nguyen*, Tuan Pham, and 1 more authorInternational Conference on Machine Learning, 2025
We introduce sliced optimal transport dataset distance (s-OTDD), a model-agnostic, embedding-agnostic approach for dataset comparison that requires no training, is robust to variations in the number of classes, and can handle disjoint label sets. The core innovation is Moment Transform Projection (MTP), which maps a label, represented as a distribution over features, to a real number. Using MTP, we derive a data point projection that transforms datasets into one-dimensional distributions. The s-OTDD is defined as the expected Wasserstein distance between the projected distributions, with respect to random projection parameters. Leveraging the closed form solution of one-dimensional optimal transport, s-OTDD achieves (near-)linear computational complexity in the number of data points and feature dimensions and is independent of the number of classes. With its geometrically meaningful projection, s-OTDD strongly correlates with the optimal transport dataset distance while being more efficient than existing dataset discrepancy measures. Moreover, it correlates well with the performance gap in transfer learning and classification accuracy in data augmentation.
- Towards Marginal Fairness Sliced Wasserstein BarycenterKhai Nguyen* , Hai Nguyen*, and Nhat HoInternational Conference on Learning Representations, 2025Spotlight Presentation [3.2%]
Spotlight
The sliced Wasserstein barycenter (SWB) is a widely acknowledged method for efficiently generalizing the averaging operation within probability measure spaces. However, achieving marginal fairness SWB, ensuring approximately equal distances from the barycenter to marginals, remains unexplored. The uniform weighted SWB is not necessarily the optimal choice to obtain the desired marginal fairness barycenter due to the heterogeneous structure of marginals and the non-optimality of the optimization. As the first attempt to tackle the problem, we define the marginal fairness sliced Wasserstein barycenter (MFSWB) as a constrained SWB problem. Due to the computational disadvantages of the formal definition, we propose two hyperparameter-free and computationally tractable surrogate MFSWB problems that implicitly minimize the distances to marginals and encourage marginal fairness at the same time. To further improve the efficiency, we perform slicing distribution selection and obtain the third surrogate definition by introducing a new slicing distribution that focuses more on marginally unfair projecting directions. We discuss the relationship of the three proposed problems and their relationship to sliced multi-marginal Wasserstein distance. Finally, we conduct experiments on finding 3D point-clouds averaging, color harmonization, and training of sliced Wasserstein autoencoder with class-fairness representation to show the favorable performance of the proposed surrogate MFSWB problems.




2024
- Hierarchical Hybrid Sliced Wasserstein: A Scalable Metric for Heterogeneous Joint DistributionsKhai Nguyen, and Nhat HoNeural Information Processing Systems, 2024
Sliced Wasserstein (SW) and Generalized Sliced Wasserstein (GSW) have been widely used in applications due to their computational and statistical scalability. However, the SW and the GSW are only defined between distributions supported on a homogeneous domain. This limitation prevents their usage in applications with heterogeneous joint distributions with marginal distributions supported on multiple different domains. Using SW and GSW directly on the joint domains cannot make a meaningful comparison since their homogeneous slicing operator i.e., Radon Transform (RT) and Generalized Radon Transform (GRT) are not expressive enough to capture the structure of the joint supports set. To address the issue, we propose two new slicing operators i.e., Partial Generalized Radon Transform (PGRT) and Hierarchical Hybrid Radon Transform (HHRT). In greater detail, PGRT is the generalization of Partial Radon Transform (PRT), which transforms a subset of function arguments non-linearly while HHRT is the composition of PRT and multiple domain-specific PGRT on marginal domain arguments. By using HHRT, we extend the SW into Hierarchical Hybrid Sliced Wasserstein (H2SW) distance which is designed specifically for comparing heterogeneous joint distributions. We then discuss the topological, statistical, and computational properties of H2SW. Finally, we demonstrate the favorable performance of H2SW in 3D mesh deformation, deep 3D mesh autoencoders, and datasets comparison.
- Sliced Wasserstein with Random-Path Projecting DirectionsKhai Nguyen, Shujian Zhang , Tam Le, and 1 more authorInternational Conference on Machine Learning, 2024
Slicing distribution selection has been used as an effective technique to improve the performance of parameter estimators based on minimizing sliced Wasserstein distance in applications. Previous works either utilize expensive optimization to select the slicing distribution or use slicing distributions that require expensive sampling methods. In this work, we propose an optimization-free slicing distribution that provides a fast sampling for the Monte Carlo estimation of expectation. In particular, we introduce the random-path projecting direction (RPD) which is constructed by leveraging the normalized difference between two random vectors following the two input measures. From the RPD, we derive the random-path slicing distribution (RPSD) and two variants of sliced Wasserstein, i.e., the Random-Path Projection Sliced Wasserstein (RPSW) and the Importance Weighted Random-Path Projection Sliced Wasserstein (IWRPSW). We then discuss the topological, statistical, and computational properties of RPSW and IWRPSW. Finally, we showcase the favorable performance of RPSW and IWRPSW in gradient flow and the training of denoising diffusion generative models on images.
- Integrating Efficient Optimal Transport and Functional Maps For Unsupervised Shape Correspondence LearningThanh Tung Le , Khai Nguyen, Shanlin Sun, and 2 more authors2024
In the realm of computer vision and graphics, accurately establishing correspondences between geometric 3D shapes is pivotal for applications like object tracking, registration, texture transfer, and statistical shape analysis. Moving beyond traditional hand-crafted and data-driven feature learning methods, we incorporate spectral methods with deep learning, focusing on functional maps (FMs) and optimal transport (OT). Traditional OT-based approaches, often reliant on entropy regularization OT in learning-based framework, face computational challenges due to their quadratic cost. Our key contribution is to employ the sliced Wasserstein distance (SWD) for OT, which is a valid fast optimal transport metric in an unsupervised shape matching framework. This unsupervised framework integrates functional map regularizers with a novel OT-based loss derived from SWD, enhancing feature alignment between shapes treated as discrete probability measures. We also introduce an adaptive refinement process utilizing entropy regularized OT, further refining feature alignments for accurate point-to-point correspondences. Our method demonstrates superior performance in non-rigid shape matching, including near-isometric and non-isometric scenarios, and excels in downstream tasks like segmentation transfer. The empirical results on diverse datasets highlight our framework’s effectiveness and generalization capabilities, setting new standards in non-rigid shape matching with efficient OT metrics and an adaptive refinement module.
- Quasi-Monte Carlo for 3D Sliced WassersteinKhai Nguyen, Nicolas Bariletto, and Nhat HoInternational Conference on Learning Representations, 2024Spotlight Presentation [5%]
Spotlight
Monte Carlo (MC) approximation has been used as the standard computation approach for the Sliced Wasserstein (SW) distance, which has an intractable expectation in its analytical form. However, the MC method is not optimal in terms of minimizing the absolute approximation error. To provide a better class of empirical SW, we propose quasi-sliced Wasserstein (QSW) approximations that rely on Quasi-Monte Carlo (QMC) methods. For a comprehensive investigation of QMC for SW, we focus on the 3D setting, specifically computing the SW between probability measures in three dimensions. In greater detail, we empirically verify various ways of constructing QMC points sets on the 3D unit-hypersphere, including Gaussian-based mapping, equal area mapping, generalized spiral points, and optimizing discrepancy energies. Furthermore, to obtain an unbiased estimation for stochastic optimization, we extend QSW into Randomized Quasi-Sliced Wasserstein (RQSW) by introducing randomness to the discussed low-discrepancy sequences. For theoretical properties, we prove the asymptotic convergence of QSW and the unbiasedness of RQSW. Finally, we conduct experiments on various 3D tasks, such as point-cloud comparison, point-cloud interpolation, image style transfer, and training deep point-cloud autoencoders, to demonstrate the favorable performance of the proposed QSW and RQSW variants.
- Sliced Wasserstein Estimation with Control VariatesKhai Nguyen, and Nhat HoInternational Conference on Learning Representations, 2024
The sliced Wasserstein (SW) distances between two probability measures are defined as the expectation of the Wasserstein distance between two one-dimensional projections of the two measures. The randomness comes from a projecting direction that is used to project the two input measures to one dimension. Due to the intractability of the expectation, Monte Carlo integration is performed to estimate the value of the SW distance. Despite having various variants, there has been no prior work that improves the Monte Carlo estimation scheme for the SW distance in terms of controlling its variance. To bridge the literature on variance reduction and the literature on the SW distance, we propose computationally efficient control variates to reduce the variance of the empirical estimation of the SW distance. The key idea is to first find Gaussian approximations of projected one-dimensional measures, then we utilize the closed-form of the Wasserstein-2 distance between two Gaussian distributions to design the control variates. In particular, we propose using a lower bound and an upper bound of the Wasserstein-2 distance between two fitted Gaussians as two computationally efficient control variates. We empirically show that the proposed control variate estimators can help to reduce the variance considerably when comparing measures over images and point-clouds. Finally, we demonstrate the favorable performance of the proposed control variate estimators in gradient flows to interpolate between two point-clouds and in deep generative modeling on standard image datasets, such as CIFAR10 and CelebA.
- Diffeomorphic Deformation via Sliced Wasserstein Distance Optimization for Cortical Surface ReconstructionInternational Conference on Learning Representations, 2024
Mesh deformation is a core task for 3D mesh reconstruction, but defining an efficient discrepancy between predicted and target meshes remains an open problem. A prevalent approach in current deep learning is the set-based approach which measures the discrepancy between two surfaces by comparing two randomly sampled point-clouds from the two meshes with Chamfer pseudo-distance. Nevertheless, the set-based approach still has limitations such as lacking a theoretical guarantee for choosing the number of points in sampled point-clouds, and the pseudo-metricity and the quadratic complexity of the Chamfer divergence. To address these issues, we propose a novel metric for learning mesh deformation. The metric is defined by sliced Wasserstein distance on meshes represented as probability measures that generalize the set-based approach. By leveraging probability measure space, we gain flexibility in encoding meshes using diverse forms of probability measures, such as continuous, empirical, and discrete measures via varifold representation. After having encoded probability measures, we can compare meshes by using the sliced Wasserstein distance which is an effective optimal transport distance with linear computational complexity and can provide a fast statistical rate for approximating the surface of meshes. Furthermore, we employ a neural ordinary differential equation (ODE) to deform the input surface into the target shape by modeling the trajectories of the points on the surface. Our experiments on cortical surface reconstruction demonstrate that our approach surpasses other competing methods in multiple datasets and metrics.
- Revisiting Deep Audio-Text Retrieval Through the Lens of TransportationManh Luong , Khai Nguyen, Nhat Ho, and 3 more authorsInternational Conference on Learning Representations, 2024
Learning-to-match (LTM) is an effective inverse optimal transport framework for learning the underlying ground metric between two sources of data, which can be further used to form the matching between them. Nevertheless, the conventional LTM framework is not scalable since it needs to use the entire dataset each time updating the parametric ground metric. To adapt the LTM framework to the deep learning setting, we propose the mini-batch learning-to-match (m-LTM) framework for audio-text retrieval problems, which is based on mini-batch subsampling and neural networks parameterized ground metric. In addition, we improve further the framework by introducing the Mahalanobis-enhanced family of ground metrics. Moreover, to cope with the noisy data correspondence problem arising from practice, we additionally propose a variant using partial optimal transport to mitigate the pairing uncertainty in training data. We conduct extensive experiments on audio-text matching problems using three datasets: AudioCaps, Clotho, and ESC-50. Results demonstrate that our proposed method is capable of learning rich and expressive joint embedding space, which achieves SOTA performance. Beyond this, the proposed m-LTM framework is able to close the modality gap across audio and text embedding, which surpasses both triplet and contrastive loss in the zero-shot sound event detection task on the ESC-50 dataset. Finally, our strategy to use partial OT with m-LTM has shown to be more noise tolerance than contrastive loss under a variant of noise ratio of training data in AudioCaps.
- Towards Convergence Rates for Parameter Estimation in Gaussian-gated Mixture of ExpertsHuy Nguyen , Trung Tin Nguyen , Khai Nguyen, and 1 more authorInternational Conference on Artificial Intelligence and Statistics, 2024
Originally introduced as a neural network for ensemble learning, mixture of experts (MoE) has recently become a fundamental building block of highly successful modern deep neural networks for heterogeneous data analysis in several applications, including those in machine learning, statistics, bioinformatics, economics, and medicine. Despite its popularity in practice, a satisfactory level of understanding of the convergence behavior of Gaussian-gated MoE parameter estimation is far from complete. The underlying reason for this challenge is the inclusion of covariates in the Gaussian gating and expert networks, which leads to their intrinsically complex interactions via partial differential equations with respect to their parameters. We address these issues by designing novel Voronoi loss functions to accurately capture heterogeneity in the maximum likelihood estimator (MLE) for resolving parameter estimation in these models. Our results reveal distinct behaviors of the MLE under two settings: the first setting is when all the location parameters in the Gaussian gating are non-zeros while the second setting is when there exists at least one zero-valued location parameter. Notably, these behaviors can be characterized by the solvability of two different systems of polynomial equations. Finally, we conduct a simulation study to verify our theoretical results.
- On Parameter Estimation in Deviated Gaussian Mixture of ExpertsHuy Nguyen , Khai Nguyen, and Nhat HoInternational Conference on Artificial Intelligence and Statistics, 2024
We consider the parameter estimation problem in the \emphdeviated Gaussian mixture of experts in which the data are generated from (1 - λ^*) g_0(Y| X) + λ^* \sum_i = 1^k_* p_i^* f(Y|h_1(X, \theta_1i^*), h_2(X, \theta_2i^*)), where X, Y are respectively covariates and the response variable, g_0(Y|X) is a known function, λ^* ∈[0, 1] is true but unknown mixing proportion, and (p_i^*, \theta_1i^*, \theta_2i^*) for 1 ≤i ≤k^* are unknown parameters of the Gaussian mixture of experts with expert functions h_1(X,.) and h_2(X,.). This problem arises from the goodness-of-fit test when we would like to test whether the data are generated from g_0(Y|X) (null hypothesis) or they are generated from the whole mixture (alternative hypothesis). Based on the algebraic structure of the expert functions and the distinguishability between g_0 and the mixture part, we design novel Voronoi-based loss functions to capture the convergence rates of the maximum likelihood estimation (MLE) for our models. We further demonstrate that our proposed loss functions are better than the generalized Wasserstein, a loss function being used in Gaussian mixture of experts for parameter estimation, at characterizing the local convergence rates of parameters.









2023
- Energy-Based Sliced Wasserstein DistanceKhai Nguyen, and Nhat HoNeural Information Processing Systems, 2023
The sliced Wasserstein (SW) distance has been widely recognized as a statistically effective and computationally efficient metric between two probability measures. A key component of the SW distance is the slicing distribution. There are two existing approaches for choosing this distribution. The first approach is using a fixed prior distribution. The second approach is optimizing for the best distribution which belongs to a parametric family of distributions and can maximize the expected distance. However, both approaches have their limitations. A fixed prior distribution is non-informative in terms of highlighting projecting directions that can discriminate two general probability measures. Doing optimization for the best distribution is often expensive and unstable. Moreover, designing the parametric family of the candidate distribution could be easily misspecified. To address the issues, we propose to design the slicing distribution as an energy-based distribution that is parameter-free and has the density proportional to an energy function of the projected one-dimensional Wasserstein distance. We then derive a novel sliced Wasserstein metric, energy-based sliced Waserstein (EBSW) distance, and investigate its topological, statistical, and computational properties via importance sampling, sampling importance resampling, and Markov Chain methods. Finally, we conduct experiments on point-cloud gradient flow, color transfer, and point-cloud reconstruction to show the favorable performance of the EBSW.
- Minimax Optimal Rate for Parameter Estimation in Multivariate Deviated ModelsDat Do , Huy Nguyen , Khai Nguyen, and 1 more authorNeural Information Processing Systems, 2023
We study the maximum likelihood estimation (MLE) in the \modelname where the data are generated from the density function (1-λ^*)h_0(x)+λ^*f(x|μ^*, Σ^*) where h_0 is a known function, λ^* ∈[0,1] and (μ^*, Σ^*) are unknown parameters to estimate. The main challenges in deriving the convergence rate of the MLE mainly come from two issues: (1) The interaction between the function h_0 and the density function f; (2) The deviated proportion λ^* can go to the extreme points of [0,1] as the sample size goes to infinity. To address these challenges, we develop the \emphdistinguishability condition to capture the linear independent relation between the function h_0 and the density function f. We then provide comprehensive convergence rates of the MLE via the vanishing rate of λ^* to 0 as well as the distinguishability of h_0 and f.
- Markovian Sliced Wasserstein Distances: Beyond Independent ProjectionsKhai Nguyen, Tongzheng Ren, and Nhat HoNeural Information Processing Systems, 2023
Sliced Wasserstein (SW) distance suffers from redundant projections due to independent uniform random projecting directions. To partially overcome the issue, max K sliced Wasserstein (Max-K-SW) distance (K≥1), seeks the best discriminative orthogonal projecting directions. Despite being able to reduce the number of projections, the metricity of Max-K-SW cannot be guaranteed in practice due to the non-optimality of the optimization. Moreover, the orthogonality constraint is also computationally expensive and might not be effective. To address the problem, we introduce a new family of SW distances, named Markovian sliced Wasserstein (MSW) distance, which imposes a first-order Markov structure on projecting directions. We discuss various members of MSW by specifying the Markov structure including the prior distribution, the transition distribution, and the burning and thinning technique. Moreover, we investigate the theoretical properties of MSW including topological properties (metricity, weak convergence, and connection to other distances), statistical properties (sample complexity, and Monte Carlo estimation error), and computational properties (computational complexity and memory complexity). Finally, we compare MSW distances with previous SW variants in various applications such as gradient flows, color transfer, and deep generative modeling to demonstrate the favorable performance of MSW.
- Robustify Transformers with Robust Kernel Density EstimationXing Han, Tongzheng Ren , Tan Nguyen, and 3 more authorsNeural Information Processing Systems, 2023
Recent advances in Transformer architecture have empowered its empirical success in various tasks across different domains. However, existing works mainly focus on improving the standard accuracy and computational cost, without considering the robustness of contaminated samples. Existing work has shown that the self-attention mechanism, which is the center of the Transformer architecture, can be viewed as a non-parametric estimator based on the well-known kernel density estimation (KDE). This motivates us to leverage the robust kernel density estimation (RKDE) in the self-attention mechanism, to alleviate the issue of the contamination of data by down-weighting the weight of bad samples in the estimation process. The modified self-attention mechanism can be incorporated into different Transformer variants. Empirical results on language modeling and image classification tasks demonstrate the effectiveness of this approach.
- Self-Attention Amortized Distributional Projection Optimization for Sliced Wasserstein Point-Cloud ReconstructionKhai Nguyen*, Dang Nguyen*, and Nhat HoInternational Conference on Machine Learning, 2023
Max sliced Wasserstein (Max-SW) distance has been widely known as a solution for redundant projections of sliced Wasserstein (SW) distance. In applications that have various independent pairs of probability measures, amortized projection optimization is utilized to predict the “max" projecting directions given two input measures instead of using projected gradient ascent multiple times. Despite being efficient, the first issue of the current framework is the violation of permutation invariance property and symmetry property. To address the issue, we propose to design amortized models based on self-attention architecture. Moreover, we adopt efficient self-attention architectures to make the computation linear in the number of supports. Secondly, Max-SW and its amortized version cannot guarantee metricity property due to the sub-optimality of the projected gradient ascent and the amortization gap. Therefore, we propose to replace Max-SW with distributional sliced Wasserstein distance with von Mises-Fisher (vMF) projecting distribution (v-DSW). Since v-DSW is a metric with any non-degenerate vMF distribution, its amortized version can guarantee the metricity when predicting the best discriminate projecting distribution. With the two improvements, we derive self-attention amortized distributional projection optimization and show its appealing performance in point-cloud reconstruction and its downstream applications.
- Fast Approximation of the Generalized Sliced-Wasserstein DistanceDung Le* , Huy* Nguyen , Khai Nguyen*, and 2 more authorsIEEE International Conference on Acoustics, Speech and Signal Processing, 2023
Generalized sliced Wasserstein distance is a variant of sliced Wasserstein distance that exploits the power of non-linear projection through a given defining function to better capture the complex structures of the probability distributions. Similar to sliced Wasserstein distance, generalized sliced Wasserstein is defined as an expectation over random projections which can be approximated by the Monte Carlo method. However, the complexity of that approximation can be expensive in high-dimensional settings. To that end, we propose to form deterministic and fast approximations of the generalized sliced Wasserstein distance by using the concentration of random projections when the defining functions are polynomial function, circular function, and neural network type function. Our approximations hinge upon an important result that one-dimensional projections of a high-dimensional random vector are approximately Gaussian.
- Hierarchical Sliced Wasserstein DistanceInternational Conference on Learning Representations, 2023
Sliced Wasserstein (SW) distance has been widely used in different application scenarios since it can be scaled to a large number of supports without suffering from the curse of dimensionality. The value of sliced Wasserstein distance is the average of transportation cost between one-dimensional representations (projections) of original measures that are obtained by Radon Transform (RT). Despite its efficiency in the number of supports, estimating the sliced Wasserstein requires a relatively large number of projections in high-dimensional settings. Therefore, for applications where the number of supports is relatively small compared with the dimension, e.g., several deep learning applications where the mini-batch approaches are utilized, the complexities from matrix multiplication of Radon Transform become the main computational bottleneck. To address this issue, we propose to derive projections by linearly and randomly combining a smaller number of projections which are named bottleneck projections. We explain the usage of these projections by introducing Hierarchical Radon Transform (HRT) which is constructed by applying Radon Transform variants recursively. We then formulate the approach into a new metric between measures, named Hierarchical Sliced Wasserstein (HSW) distance. By proving the injectivity of HRT, we derive the metricity of HSW. Moreover, we investigate the theoretical properties of HSW including its connection to SW variants and its computational and sample complexities. Finally, we compare the computational cost and generative quality of HSW with the conventional SW on the task of deep generative modeling using various benchmark datasets including CIFAR10, CelebA, and Tiny ImageNet.
- Model Fusion of Heterogeneous Neural Networks via Cross-Layer AlignmentDang Nguyen , Trang Nguyen , Khai Nguyen, and 3 more authorsIEEE International Conference on Acoustics, Speech and Signal Processing, 2023
Layer-wise model fusion via optimal transport, named OTFusion, applies soft neuron association for unifying different pre-trained networks to save computational resources. While enjoying its success, OTFusion requires the input networks to have the same number of layers. To address this issue, we propose a novel model fusion framework, named CLAFusion, to fuse neural networks with a different number of layers, which we refer to as heterogeneous neural networks, via cross-layer alignment. The cross-layer alignment problem, which is an unbalanced assignment problem, can be solved efficiently using dynamic programming. Based on the cross-layer alignment, our framework balances the number of layers of neural networks before applying layer-wise model fusion. Our experiments indicate that CLAFusion, with an extra finetuning process, improves the accuracy of residual networks on CIFAR10 and CIFAR100 datasets. Furthermore, we explore its practical usage for model compression and knowledge distillation when applying to the teacher-student setting.








2022
- Revisiting Sliced Wasserstein on Images: From Vectorization to ConvolutionKhai Nguyen, and Nhat HoNeural Information Processing Systems, 2022
The conventional sliced Wasserstein is defined between two probability measures that have realizations as vectors. When comparing two probability measures over images, practitioners first need to vectorize images and then project them to one-dimensional space by using matrix multiplication between the sample matrix and the projection matrix. After that, the sliced Wasserstein is evaluated by averaging the two corresponding one-dimensional projected probability measures. However, this approach has two limitations. The first limitation is that the spatial structure of images is not captured efficiently by the vectorization step; therefore, the later slicing process becomes harder to gather the discrepancy information. The second limitation is memory inefficiency since each slicing direction is a vector that has the same dimension as the images. To address these limitations, we propose novel slicing methods for sliced Wasserstein between probability measures over images that are based on the convolution operators. We derive convolution sliced Wasserstein (CSW) and its variants via incorporating stride, dilation, and non-linear activation function into the convolution operators. We investigate the metricity of CSW as well as its sample complexity, its computational complexity, and its connection to conventional sliced Wasserstein distances. Finally, we demonstrate the favorable performance of CSW over the conventional sliced Wasserstein in comparing probability measures over images and in training deep generative modeling on images.
- Amortized Projection Optimization for Sliced Wasserstein Generative ModelsKhai Nguyen, and Nhat HoNeural Information Processing Systems, 2022
The conventional sliced Wasserstein is defined between two probability measures that have realizations as vectors. When comparing two probability measures over images, practitioners first need to vectorize images and then project them to one-dimensional space by using matrix multiplication between the sample matrix and the projection matrix. After that, the sliced Wasserstein is evaluated by averaging the two corresponding one-dimensional projected probability measures. However, this approach has two limitations. The first limitation is that the spatial structure of images is not captured efficiently by the vectorization step; therefore, the later slicing process becomes harder to gather the discrepancy information. The second limitation is memory inefficiency since each slicing direction is a vector that has the same dimension as the images. To address these limitations, we propose novel slicing methods for sliced Wasserstein between probability measures over images that are based on the convolution operators. We derive convolution sliced Wasserstein (CSW) and its variants via incorporating stride, dilation, and non-linear activation function into the convolution operators. We investigate the metricity of CSW as well as its sample complexity, its computational complexity, and its connection to conventional sliced Wasserstein distances. Finally, we demonstrate the favorable performance of CSW over the conventional sliced Wasserstein in comparing probability measures over images and in training deep generative modeling on images.
- Fourierformer: Transformer meets generalized Fourier integral theoremTan Nguyen, Minh Pham , Tam Nguyen, and 3 more authorsNeural Information Processing Systems, 2022
Multi-head attention empowers the recent success of transformers, the state-of-the-art models that have achieved remarkable success in sequence modeling and beyond. These attention mechanisms compute the pairwise dot products between the queries and keys, which results from the use of unnormalized Gaussian kernels with the assumption that the queries follow a mixture of Gaussian distribution. There is no guarantee that this assumption is valid in practice. In response, we first interpret attention in transformers as a nonparametric kernel regression. We then propose the FourierFormer, a new class of transformers in which the dot-product kernels are replaced by the novel generalized Fourier integral kernels. Different from the dot-product kernels, where we need to choose a good covariance matrix to capture the dependency of the features of data, the generalized Fourier integral kernels can automatically capture such dependency and remove the need to tune the covariance matrix. We theoretically prove that our proposed Fourier integral kernels can efficiently approximate any key and query distributions. Compared to the conventional transformers with dot-product attention, FourierFormers attain better accuracy and reduce the redundancy between attention heads. We empirically corroborate the advantages of FourierFormers over the baseline transformers in a variety of practical applications including language modeling and image classification.
- Improving Transformer with an Admixture of Attention HeadsTan Nguyen , Tam Nguyen, Hai Do, and 6 more authorsNeural Information Processing Systems, 2022
Multi-head attention empowers the recent success of transformers, the state-of-the-art models that have achieved remarkable success in sequence modeling and beyond. These attention mechanisms compute the pairwise dot products between the queries and keys, which results from the use of unnormalized Gaussian kernels with the assumption that the queries follow a mixture of Gaussian distribution. There is no guarantee that this assumption is valid in practice. In response, we first interpret attention in transformers as a nonparametric kernel regression. We then propose the FourierFormer, a new class of transformers in which the dot-product kernels are replaced by the novel generalized Fourier integral kernels. Different from the dot-product kernels, where we need to choose a good covariance matrix to capture the dependency of the features of data, the generalized Fourier integral kernels can automatically capture such dependency and remove the need to tune the covariance matrix. We theoretically prove that our proposed Fourier integral kernels can efficiently approximate any key and query distributions. Compared to the conventional transformers with dot-product attention, FourierFormers attain better accuracy and reduce the redundancy between attention heads. We empirically corroborate the advantages of FourierFormers over the baseline transformers in a variety of practical applications including language modeling and image classification.
- Improving Mini-batch Optimal Transport via Partial TransportationKhai Nguyen*, Dang Nguyen*, The-Anh Vu Le, and 2 more authorsInternational Conference on Machine Learning, 2022
Mini-batch optimal transport (m-OT) has been widely used recently to deal with the memory issue of OT in large-scale applications. Despite their practicality, m-OT suffers from misspecified mappings, namely, mappings that are optimal on the mini-batch level but are partially wrong in the comparison with the optimal transportation plan between the original measures. Motivated by the misspecified mappings issue, we propose a novel mini-batch method by using partial optimal transport (POT) between mini-batch empirical measures, which we refer to as mini-batch partial optimal transport (m-POT). Leveraging the insight from the partial transportation, we explain the source of misspecified mappings from the m-OT and motivate why limiting the amount of transported masses among mini-batches via POT can alleviate the incorrect mappings. Finally, we carry out extensive experiments on various applications such as deep domain adaptation, partial domain adaptation, deep generative model, color transfer, and gradient flow to demonstrate the favorable performance of m-POT compared to current mini-batch methods.
- On Transportation of Mini-batches: A Hierarchical ApproachKhai Nguyen, Dang Nguyen , Quoc Nguyen, and 5 more authorsInternational Conference on Machine Learning, 2022
Mini-batch optimal transport (m-OT) has been successfully used in practical applications that involve probability measures with a very high number of supports. The m-OT solves several smaller optimal transport problems and then returns the average of their costs and transportation plans. Despite its scalability advantage, the m-OT does not consider the relationship between mini-batches which leads to undesirable estimation. Moreover, the m-OT does not approximate a proper metric between probability measures since the identity property is not satisfied. To address these problems, we propose a novel mini-batch scheme for optimal transport, named Batch of Mini-batches Optimal Transport (BoMb-OT), that finds the optimal coupling between mini-batches and it can be seen as an approximation to a well-defined distance on the space of probability measures. Furthermore, we show that the m-OT is a limit of the entropic regularized version of the BoMb-OT when the regularized parameter goes to infinity. Finally, we carry out experiments on various applications including deep generative models, deep domain adaptation, approximate Bayesian computation, color transfer, and gradient flow to show that the BoMb-OT can be widely applied and performs well in various applications.
- On Multimarginal Partial Optimal Transport: Equivalent Forms and Computational ComplexityKhang Le , Huy Nguyen , Khai Nguyen, and 2 more authorsInternational Conference on Artificial Intelligence and Statistics, 2022
We study the multi-marginal partial optimal transport (POT) problem between discrete (unbalanced) measures with at most supports. We first prove that we can obtain two equivalent forms of the multimarginal POT problem in terms of the multimarginal optimal transport problem via novel extensions of cost tensors. The first equivalent form is derived under the assumptions that the total masses of each measure are sufficiently close while the second equivalent form does not require any conditions on these masses but at the price of more sophisticated extended cost tensor. Our proof techniques for obtaining these equivalent forms rely on novel procedures of moving mass in graph theory to push transportation plan into appropriate regions. Finally, based on the equivalent forms, we develop an optimization algorithm, named the ApproxMPOT algorithm, that builds upon the Sinkhorn algorithm for solving the entropic regularized multimarginal optimal transport. We demonstrate that the ApproxMPOT algorithm can approximate the optimal value of multimarginal POT problem with a computational complexity upper bound of the order \bigOtil (m^ 3 (n+ 1)^m/\varepsilon^ 2) where stands for the desired tolerance.







2021
- Structured Dropout Variational Inference for Bayesian Neural NetworksSon Nguyen , Duong Nguyen , Khai Nguyen, and 3 more authorsNeural Information Processing Systems, 2021
Approximate inference in Bayesian deep networks exhibits a dilemma of how to yield high fidelity posterior approximations while maintaining computational efficiency and scalability. We tackle this challenge by introducing a novel variational structured approximation inspired by the Bayesian interpretation of Dropout regularization. Concretely, we focus on the inflexibility of the factorized structure in Dropout posterior and then propose an improved method called Variational Structured Dropout (VSD). VSD employs an orthogonal transformation to learn a structured representation on the variational Gaussian noise with plausible complexity, and consequently induces statistical dependencies in the approximate posterior. Theoretically, VSD successfully addresses the pathologies of previous Variational Dropout methods and thus offers a standard Bayesian justification. We further show that VSD induces an adaptive regularization term with several desirable properties which contribute to better generalization. Finally, we conduct extensive experiments on standard benchmarks to demonstrate the effectiveness of VSD over state-of-the-art variational methods on predictive accuracy, uncertainty estimation, and out-of-distribution detection.
- Improving Relational Regularized Autoencoders with Spherical Sliced Fused Gromov WassersteinKhai Nguyen , Son Nguyen, Nhat Ho, and 2 more authorsInternational Conference on Learning Representations, 2021
Relational regularized autoencoder (RAE) is a framework to learn the distribution of data by minimizing a reconstruction loss together with a relational regularization on the prior of latent space. A recent attempt to reduce the inner discrepancy between the prior and aggregated posterior distributions is to incorporate sliced fused Gromov-Wasserstein (SFG) between these distributions. That approach has a weakness since it treats every slicing direction similarly, meanwhile several directions are not useful for the discriminative task. To improve the discrepancy and consequently the relational regularization, we propose a new relational discrepancy, named spherical sliced fused Gromov Wasserstein (SSFG), that can find an important area of projections characterized by a von Mises-Fisher distribution. Then, we introduce two variants of SSFG to improve its performance. The first variant, named mixture spherical sliced fused Gromov Wasserstein (MSSFG), replaces the vMF distribution by a mixture of von Mises-Fisher distributions to capture multiple important areas of directions that are far from each other. The second variant, named power spherical sliced fused Gromov Wasserstein (PSSFG), replaces the vMF distribution by a power spherical distribution to improve the sampling time of the vMF distribution in high dimension settings. We then apply the new discrepancies to the RAE framework to achieve its new variants. Finally, we conduct extensive experiments to show that the new autoencoders have favorable performance in learning latent manifold structure, image generation, and reconstruction.
- Distributional Sliced-Wasserstein and Applications to Generative ModelingKhai Nguyen, Nhat Ho, Tung Pham, and 1 more authorInternational Conference on Learning Representations, 2021Spotlight Presentation [3.78%]
Spotlight
Sliced-Wasserstein distance (SW) and its variant, Max Sliced-Wasserstein distance (Max-SW), have been used widely in the recent years due to their fast computation and scalability even when the probability measures lie in a very high dimensional space. However, SW requires many unnecessary projection samples to approximate its value while Max-SW only uses the most important projection, which ignores the information of other useful directions. In order to account for these weaknesses, we propose a novel distance, named Distributional Sliced-Wasserstein distance (DSW), that finds an optimal distribution over projections that can balance between exploring distinctive projecting directions and the informativeness of projections themselves. We show that the DSW is a generalization of Max-SW, and it can be computed efficiently by searching for the optimal push-forward measure over a set of probability measures over the unit sphere satisfying certain regularizing constraints that favor distinct directions. Finally, we conduct extensive experiments with large-scale datasets to demonstrate the favorable performances of the proposed distances over the previous sliced-based distances in generative modeling applications.


